Incident clustering, also known as event clustering or anomaly clustering, is a technique used in data analysis and machine learning to group similar incidents or events together based on their characteristics or patterns.
In order to deep dive into this, we used sklearn and matplotlib to both do machine learning and visualize results in an easy way.
In few words:
- Scikit-learn is a powerful and popular open-source machine learning library in Python. It provides a wide range of tools for various machine learning tasks such as classification, regression, clustering, dimensionality reduction, and more. Scikit-learn is built on top of other Python libraries like NumPy, SciPy, and matplotlib and integrates well with the scientific Python ecosystem.
- Matplotlib is a 2D plotting library in Python that allows you to create a wide variety of static, animated, and interactive visualizations. It is highly customizable and can be used to visualize data in the form of line plots, scatter plots, bar plots, histograms, and more.
The main idea is quite simple - clustering incidents and try to find “clusters” - aka ~incidents categories so that we group them and go from 900 dedicated incidents to 10 categories, easier when we want to tackle big subjects which will ease our work in the upcoming days.
Since we will deal with incidents written by users (and mainly) English speakers, we will use NLTK which is a powerful Python library for working with human language data, particularly text processing and analysis. NLTK provides a wide range of tools and resources for tasks such as tokenization, stemming, lemmatization, part-of-speech tagging, syntactic parsing, and more. It is widely used in the fields of natural language processing (NLP), computational linguistics, and text analytics.
Also, as we try to find root causes of multiple incidents, we will perform TF-IDF (Term Frequency-Inverse Document Frequency) vectorization, a popular technique used in natural language processing (NLP) and information retrieval to convert a collection of text documents into numerical vectors. It aims to represent the importance of words in each document relative to the entire corpus. In our case, our incidents.
We created a simple function to remove stop words from any string:
def remove_stop_words(string):
stop_words = set(stopwords.words("english"))
string_tokens = word_tokenize(string)
string_tokens = [
token for token in string_tokens if token.lower() not in stop_words
]
return " ".join(string_tokens)
Then, come the interesting part where we load all incidents, and perform the TF-IDF vectorization on incident descriptions. In our case, we went for that field, it could have been any other. Also, if we wanted to perform it on multiple fields, we could have appended all those fields together.
# Load incidents from JSON file
with open("incidents.json") as f:
incidents = json.load(f)
# Extract relevant information from incidents
incident_numbers = []
descriptions = []
for incident in incidents["records"]:
incident_numbers.append(incident["number"])
description = remove_stop_words(incident["short_description"])
descriptions.append(description)
# Perform TF-IDF vectorization on incident descriptions
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(descriptions)
After getting our vectorized result, we’re able to perform K-Means clustering, a popular unsupervised machine learning algorithm used for clustering data points into K distinct clusters based on their similarity. It is a straightforward and efficient algorithm that is widely used for various data analysis and pattern recognition tasks. In our case, this is perfect! We just specify the number of clusterrs we want (there’s a bit of trial and error here and where vizualisation of those clusters comes in).
# Perform K-means clustering
num_clusters = 10 # Set the desired number of clusters
kmeans = KMeans(n_clusters=num_clusters)
kmeans.fit(X)
# Assign cluster labels to incidents
cluster_labels = kmeans.labels_
# Print cluster assignments with incident criticality
for i in range(len(incident_numbers)):
incident_number = incident_numbers[i]
description = descriptions[i]
cluster_label = cluster_labels[i]
print(f"Incident: {incident_number}")
print(f"Description: {description}")
print(f"Cluster: {cluster_label}")
print()
# Print cluster centroids (representative incidents)
print("Cluster Centroids:")
for cluster_id, centroid in enumerate(kmeans.cluster_centers_):
centroid_idx = centroid.argsort()[::-1]
print(f"Cluster {cluster_id}:")
for idx in centroid_idx[:5]: # Print top 5 words in centroid
print(f"- {vectorizer.get_feature_names_out()[idx]}")
print()
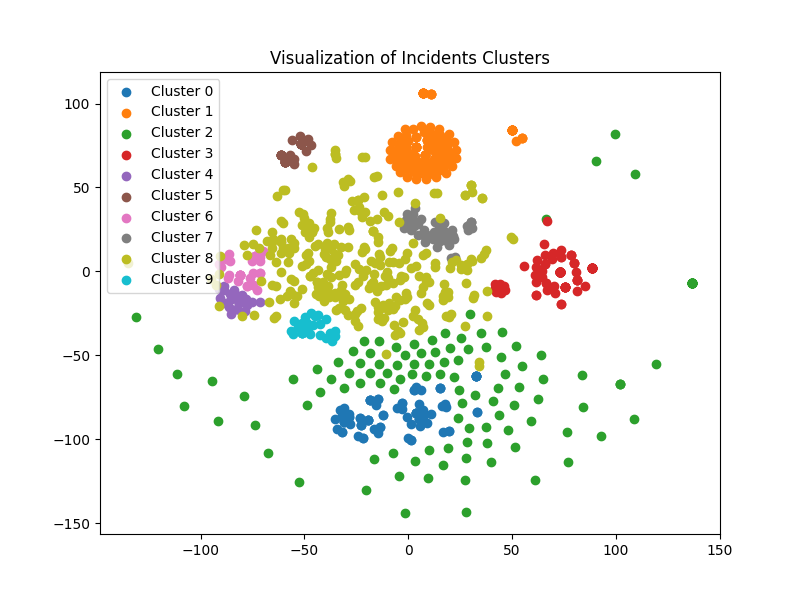
This is great as this will show us in the command line the different clusters “centroids” (aka the main criteria which led to that cluster) but this is where vizualisation is also really important. We’re using t-SNE (t-distributed Stochastic Neighbor Embedding) a dimensionality reduction technique used for visualizing high-dimensional data in a lower-dimensional space. It is particularly useful for visualizing complex datasets and preserving the local structure and relationships between data points.
# Perform t-SNE to reduce dimensionality for visualization
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X.toarray())
# Visualize clusters
plt.figure(figsize=(8, 6))
for i in range(num_clusters):
plt.scatter(
X_tsne[cluster_labels == i, 0],
X_tsne[cluster_labels == i, 1],
label=f"Cluster {i}",
)
plt.title("Visualization of Incidents Clusters")
plt.legend()
plt.show()
And… that’s it! Here is an example on 900 incidents which are categorised within 10 clusters and the results are really interesting. There would be way more on that as we could learn from previous incidents (and go from unsupervised to supervised) but also have some API capabilities to train the model directly with a single HTTP request.